03 — HARDWARE
$40 Dual-Channel System
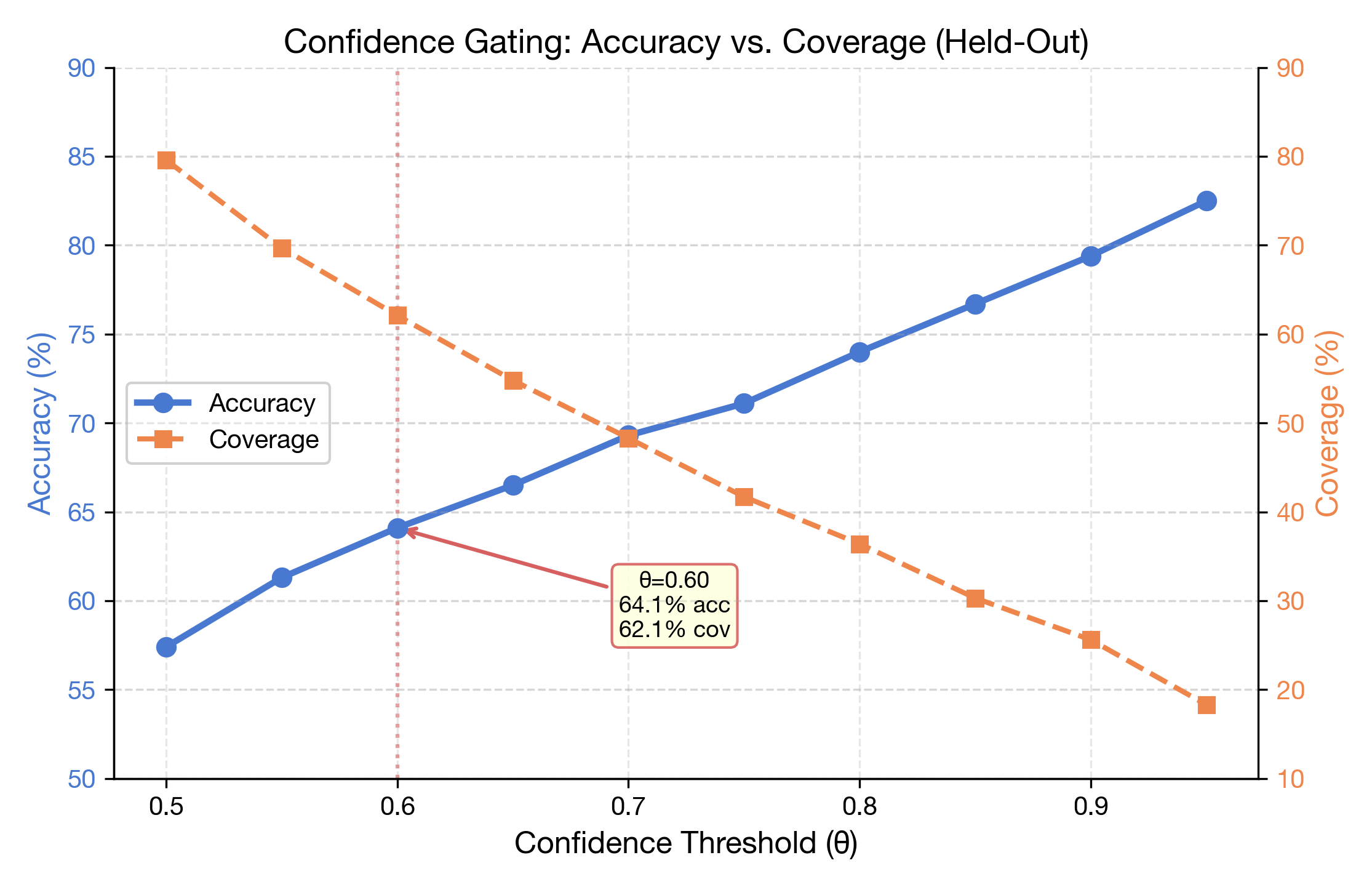
ELECTRODE PLACEMENT
SYSTEM ARCHITECTURE
Originally designed as 3-channel. The third AD8232 failed mid-project. Used both mastoid bones behind the ear as a shared ground reference → 2 active channels remained.
CH 1
AD8232 #1
Mentalis/Chin
MCU
ESP32
250 Hz ADC
USB Serial
Python
pyserial
CH 2
AD8232 #2
Throat/Under-chin
Y-splitter for shared ground reference. 3.5mm electrode cables. Ag/AgCl gel electrodes.
Total Cost
$40
Channels
2 (differential)
ADC Resolution
12-bit (4,096 levels)
Sampling Rate
250 Hz per channel
Sensor Bandpass
0.5–40 Hz
Vocabulary
6 commands (UP, DOWN, LEFT, RIGHT, SILENCE, NOISE)
Total Data
4,033 CSVs (87 MB)
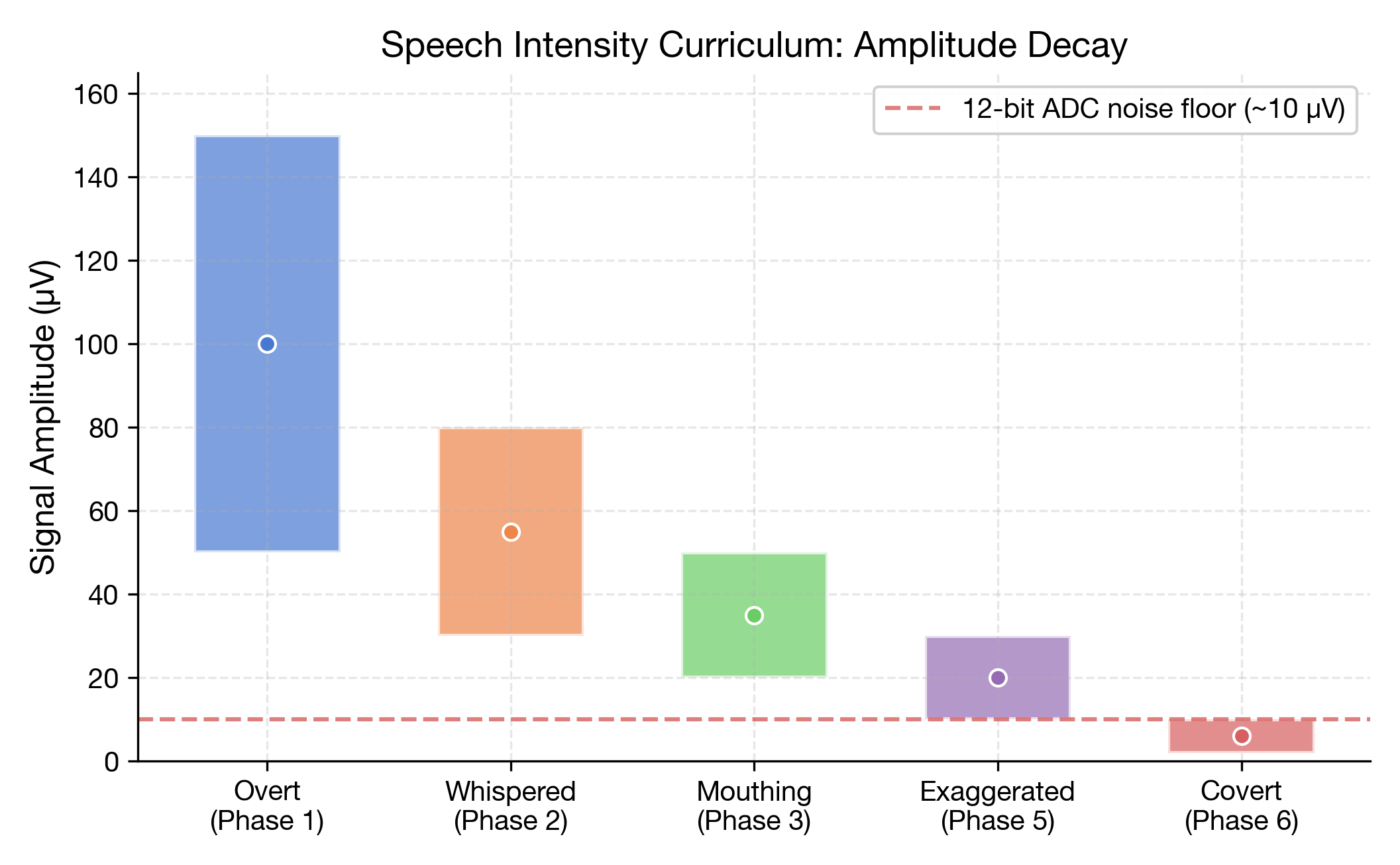
Key insight: The AD8232's bandpass (0.5–40 Hz) matches the range MIT AlterEgo and OpenBCI use for sEMG signal processing — likely coincidental, but it turns out to be sufficient to capture the onset burst that carries the discriminative signal. No hardware modification needed.